Read the Freaking Documentation
During my work on instrumentation in LLVM, I tried several simple loop IR examples to verify that computed basic block frequency is correct. A quite useful tool which helps with understanding IR files is CFGPrinter which creates a .dot file with a graphical description of the control flow graph. It can be invoked with flag -dot-cfg or -view-cfg to directly open resulting graph in a visualizer.
Soon I discovered that the pass cannot handle correctly IR files with profiling information. I started with the simplest example one can imagine when trying to verify correctness of basic block frequency:
void f(double * arr, int count)
{
for(int i = 0; i < count; ++i) {
arr[i] += 1.1;
}
}
This function is used with a standard main function which calls f with an array of length 200. I compiled both translation units separately to prevent inlining and I used -fno-vectorize -fno-unroll-loops to prevent loop optimizations which change the control-flow graph of a loop and make it much harder to understand block frequencies. The listing presents IR with embedded profiling information. There are four basic blocks in this function, the entry block, loop preheader %4, loop body %7 and exit block %6.
Even though this is a perfectly fine IR with correctly embedded metadata, the CFGPrinter pass would generate an incorrect dot file.
digraph "CFG for '_Z1fPdi' function" {
label="CFG for '_Z1fPdi' function";
Node0x5612742de010 [shape=record,label="{%2:\l %3 = icmp sgt i32 %1, 0\l br i1 %3, label %4, label %6, !prof !30\l|{<s0>T|<s1>F}}"];
Node0x5612742de010:s0 -> Node0x5612742de780["];
Node0x5612742de010:s1 -> Node0x5612742de7d0["];
Node0x5612742de780 [shape=record,label="{%4:\l\l %5 = zext i32 %1 to i64\l br label %7\l}"];
Node0x5612742de780 -> Node0x5612742df820;
Node0x5612742de7d0 [shape=record,label="{%6:\l\l ret void\l}"];
Node0x5612742df820 [shape=record,label="{%7:\l\l %8 = phi i64 [ 0, %4 ], [ %12, %7 ]\l %9 = getelementptr inbounds double, double* %0, i64 %8\l %10 = load double, double* %9, align 8, !tbaa !31\l %11 = fadd double %10, 1.100000e+00\l store double %11, double* %9, align 8, !tbaa !31\l %12 = add nuw nsw i64 %8, 1\l %13 = icmp eq i64 %12, %5\l br i1 %13, label %6, label %7, !prof !35\l|{<s0>T|<s1>F}}"];
Node0x5612742df820:s0 -> Node0x5612742de7d0["];
Node0x5612742df820:s1 -> Node0x5612742df820["];
}
The issue is not hard to recognize: edge labels are not generated correctly and every not closed quotation mark should be instead a proper edge label. It does not seem to be a misprint of an empty label because PGO provides information on branch weights. What should we expect here is something more like label="W:100" where 100 might be any value taken by a weight. So far the problem seems to be simple, perhaps a specific print function is taking path which is not properly tested. We can fix that.
A quick inspection of functions used by the pass located the problem in getEdgeAttributes function in the header llvm/Analysis/CFGPrinter.h. It checks for several conditions such as non-existing weight, when in fact an empty string is returned. But it’s not happening in our case since the control flow reaches the very last return statement which is surprisingly simple.
std::string getEdgeAttributes(const BasicBlock *Node, succ_const_iterator I, const Function *F) {
...
Twine Attrs = "label=\"W:" + Twine(Weight->getZExtValue()) + "\"";
return Attrs.str();
}
Twine appears to be some kind of a string converter but there is no clear indication of what went wrong in my case. I immediately suspected either a failed implementation of copy constructor or addition operator or a simple bug in the str method. As a first step, I tried using LLVM streams such as llvm::outs().
llvm::outs() << ("label=\"W:" + Twine(Weight->getZExtValue()) + "\"").str() << '\n';
Surprisingly, this worked! The output is now correct and the next step is obvious - find out where is the difference in behavior between str and print functionality. In this case, str creates a SmallString vector, writes the resulting string to it with toVector function which internally uses raw_svector_stream. Since it’s yet another implementation of LLVM raw_ostream interface, the result is processed with the very same print function. Dead end, there’s no important distinction here.
It seems that we won’t fix this bug without investigating Twine. Twine is used in LLVM primarily for cheap and lazy string concatenation without using dynamic memory allocation. Internally we have a complex, tree-like data structure with nodes storing various types. The easiest implementation of such pattern consists of polymorphic types to abstract away the actual content of a node. Yet as usual, the easiest solution is not the one providing the best performance. To avoid the cost dynamic calls, dynamic memory allocation and vtables in every object, Twine uses a union to store values and an enum to remember the type of stored value. But how it relates to our problem? The documentation already gives us a hint - Twine objects should not be stored since they use temporary objects as its input. Indeed, a union-based storage captures input data as pointers. And here I have to admit that I spent a considerable amount of time on reading and debugging the code before I even though of looking at LLVM docs. Additionally, I tried to reproduce the issue in a simple application and failed which made the bug much more mysterious and fooled me to believe that there is a much serious issue with memory management. My mistake, I guess. If I started with documentation, I would save a lot time.
With this information, the bug is obvious since Twine creation and string conversion are split into two statements. The problem is caused by storing a complex Twine structure which references temporary objects, in this case, it’s mostly another Twine instance which is going to be destroyed as soon as the initialization is finished. I verified this by inspecting the internal tree and found out that memory contents are corrupted. The conversion utility works flawlessly but it never receives a correct Twine object. And I don’t have a perfect explanation of why this problem could not reproduced in a toy application. Perhaps the order of variables on the stack was different and I was successful in accessing correct Twine structure before the memory was overwritten by another variable.
Finally we obtain a readable and clear depiction of control-flow in our function.
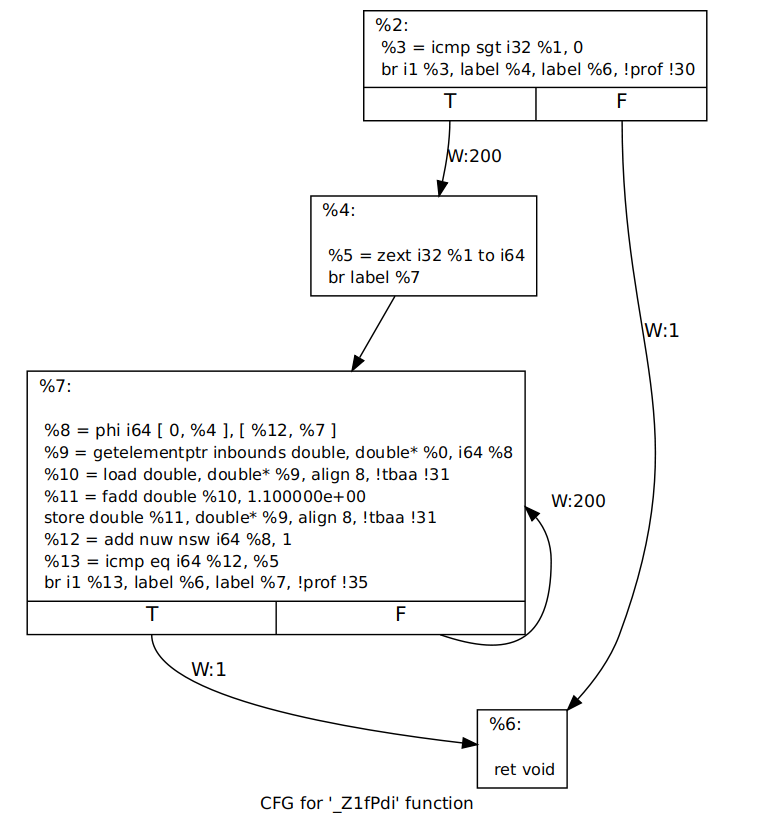
Of course, I can not be the first one to find this problem. A bug report was filed in April 2018 on LLVM bug tracker with exactly the same problem - Undefined behavior in CFGPrinter due to Twine misuse. A patch was provided in a separate repository and maybe that’s why no one bothered to fix it in the last six months. I decided to create a very simple patch and proposed it on Phabricator - review D52933. Hopefully, it will go through!
There are three lessons here. Even a proper documentation of specific features and requirements might not prevent experienced developers of misusing a library. Maybe we need a [potentially_unsafe] attribute specifier for functions and types to make developers more aware? The point here is not to discourage people from using it but merely remind to read the documentation before. Many good APIs allow writing code immediately, simply by inspecting function names and their respective parameters. However, not every library is meant to be used that way.
After finding the bug, I talked with a local LLVM guru and asked him about Twine. His response was basically: “yeah, Twine is a constant problem generator, just use std::to_string”. Here comes the second lesson which is more personal - if you look for a bug and discover it somewhere in an in-house, custom piece of software, think twice if you really want to spend time looking for a source of the problem. However, if it smells just a little bit of dangling pointers - send a bug report and run like hell.
And the last lesson? Read the Freaking Documentation.
Enjoy Reading This Article?
Here are some more articles you might like to read next:
- C++ for Serverless - Always Faster?
- Generating documentation with AI Agents
- Cross-compiling C++ to serverless ARM
- Installing FetchContent targets in CMake
- Google Summer of Code 2023
- Debugging the debugger
- Remote Bash scripts with SSH
- JSON in Bash and CLI with jq
- Relative paths in LaTeX.
- C++ Toolchain with Taint Analysis